- 搜索

中国东谈主工智能初创公司深度求索(DeepSeek)3月24日深夜低调上线了DeepSeek-V3的新版块DeepSeek-V3-0324,参数目为6850亿,在代码、数学、推理等多个方面的智商再次显贵晋升,以致代码智商追平好意思国Anthropic公司大模子Claude 3.7。
不外,外界关于DeepSeek-V3-0324的关注并不单是因为该版块的智商晋升,而是算计它的发布是否意味着DeepSeek更新一代的V4与R2大模子的发布不远了。
在回答《环球时报》记者相关DeepSeek-V3新版块有哪些智商晋升时,DeepSeek暗示,一是新版块代码智商显贵晋升,接近Claude 3.7水平。举例,灵验户在实测中发现,V3-0324能一次性生成800行无格外的网页代码,并竣事动态反应式布局和交互效能。二是数学与逻辑推明智商增强。举例经典的“4升水壶问题”和数学竞赛题(如AIME 2025题目),部分发扬接近专科推理模子。三是模子架构与开源生态。V3-0324聘请MIT许可证,允许解放修改、分发及生意化哄骗,进一步缩小了竖立者的使用门槛。
清华大学新闻学院、东谈主工智能学院老师沈阳25日对《环球时报》记者暗示,DeepSeek-V3-0324不仅是V3系列的一次迭代,更是中国AI技艺崛起的又一力证。其在性能、效能和开源政策上的轮廓上风使其在民众大言语模子限制占据紧迫地位。将来,DeepSeek可能通过推明智商晋升和多模态扩张来牢固技艺当先上风,同期在中好意思竞争和社区生态中寻找均衡。沈阳合计,DeepSeek-V3-0324的发布看似是一次“小更新”,但其性能当先标明该团队可能在为后续紧要版块(如传言中的DeepSeek-R2或V4)铺路。
路透社本年2月底引述3名知情东谈主士的说法声称,DeepSeek原计较在本年5月初发布R2,但咫尺但愿尽早推出,具体时刻尚未透露。此外,DeepSeek但愿新模子在代码生成和多言语推理方面的发扬进一步晋升。不外,外媒的关联传言并莫得获得DeepSeek公司的说明与复兴。
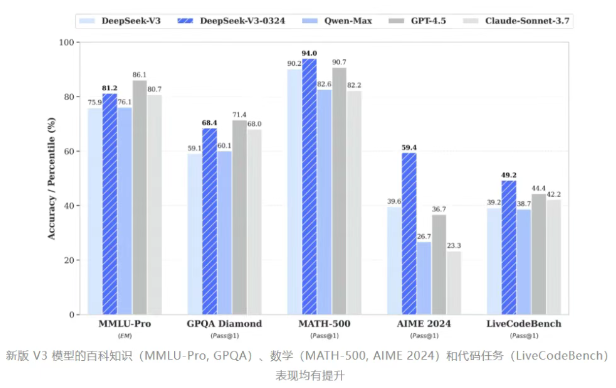
沈阳暗示,DeepSeek-V3-0324的推出进一步突显中国AI企业在技艺与资本上的竞争力。好意思国对华GPU出口罢休可能促使中国企业加快国产硬件适配,同期其开源形式或激发西方厂商的连锁看成,举例推出更强闭源模子。2025年可能是中好意思AI竞争的分水岭。
沈阳合计,在OpenAI公司的GPT大模子要把通用大模子和推理大模子交融在一皆的配景下凯发·k8国际app(中国)官方网站,外界关注包括DeepSeek在内的中国头部大模子是不是最终也会出现这种吞并的趋势。“这种可能是存在的,因为关于用户来说,并不善良大模子在复兴自己问题时用的是什么类型的模子,更善良大模子能不可给出更为智能、合理的参考谜底。”(据环球时报)
